As I read the various things that are being written about Observability as it relates to the monitoring, DevOps, Site Reliability Engineering, the performance and availability of highly complex and dynamic distributed systems, I find myself questioning most of it and disagreeing with a good bit of it.
The Definition of Observability
Many people start with the definition of Observability in Wikipedia – “In control theory, observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs. The observability and controllability of a system are mathematical duals”.
Using this definition of Observability as it relates to monitoring has several problems:
- Understanding a system based upon knowledge of its external outputs. Well it turns out in most distributed application systems, the inputs are just as important as the outputs. In fact the outputs (units of work) are almost always the result of inputs by a user or another application. One of the Four Golden Signals, latency, is all about how long it takes the system to respond with an output to an input. Another Golden Signal, throughput is all about how many inputs and outputs are occurring per unit of time. Error rate is about how often the system fails to respond properly to an input.
- Inferring the internal state of a system from the outputs. Inference is a very dangerous thing to do, and in my mind flies in the face of what Observability ought to mean. Observability ought to mean that we know with 100% certainty what the state of the system is because we have the information at hand that lets us know this in a deterministic manner (more about this below).
- Observability and controllability are mathematical duals. The ability to control a system is absolutely dependent upon reliable, accurate, deterministic, and comprehensive signals that can be counted on as the basis of a control action. Those signals need to be based upon both the inputs to the system and the outputs of the system. Taking a control action based upon an inference is somewhere in between stupid and dangerous. Look at the MCAS system on the Boeing 737Max. The MCAS system inferred (from bad sensor data) that the nose was pointing up, took a control action to point the nose down which caused two planes to crash and to tragically kill 347 people.
- It presumes that the system has outputs which can be used to observe its behavior. Well the most important parts of most systems (the applications) do not expose any outputs or metrics by which we can judge the behavior of the applications themselves. How to best do this, is in my opinion the most important part of the Observability debate.
Different People’s (Vendors) Interpretation of Observability
If you have been around long enough to remember when “Cloud” became a phenomenon and a popular term, everyone rushed to embrace the term and to define it to benefit their product offerings. As a result we got IaaS, PaaS, and SaaS, and as a result and we got Private Cloud, Hybrid Cloud and Public Cloud. We also got a lot of “Cloud Washing” which was good intentioned marketing departments trying to associate their products with cloud whether they had anything to do with cloud or not.
We appear to be in the phase of Observability Washing right now. This is not to be critical of anyone who is attempting to define Observability in their own terms it is just an observation that we have widely differing interpretations of the concept.
In a very comprehensive blog post up on Medium, Monitoring and Observability, Cindy Sridharan pretty much defines Observability as a superset of monitoring and testing.

In What is Observability, Dmitry Melanchenko on the Salesforce Engineering team states that the objective of Observability is to “To make a complex system as transparent as possible to those who operate it”. Now this is a definition that I can get behind because it suggests that Observability is about having the data (whatever that might be) required to understand the system.
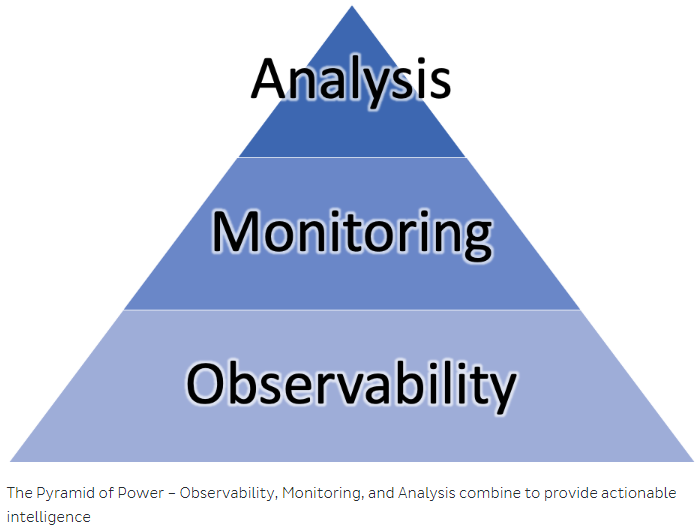
In Observability vs. Monitoring, Instana makes the case that Observability is the lowest part of a three tier architecture with monitoring and analysis sitting on top of Observability as shown below. Here again Observability is defined as being all about the underlying data that describes the state of a system.
In “The 10 Principles of Observability: Guideposts on the Path to Success with Modern Software”, New Relic lays out the set of attributes that a monitoring system must have to fully deliver the benefits of Observability to the organization.
In, “Observability a Three Year Retrospective”, Charity Majors of Honeycomb declares that you cannot achieve Observability with traditional APM tools and logging tools, and must take the approach of instrumenting your code because, “After all, metrics, logs, and traces can trivially be derived from arbitrarily wide structured events; the reverse is not true”. Of all of the things that I have read about Observability I disagree with this the most.
What Observability Ought to Mean
So I am going to be bold here and attempt to redefine a term that a lot of really smart people have already written extensively about. In my humble opinion, Observability ought to be all about the data:
- We have the data in whatever form it may be (metrics, logs, traces, topology maps, dependency maps, configuration over time, etc.) required to understand the behavior of the system, understand when something has gone wrong and understand why it has gone wrong (root cause).
- We have the Four Golden Signals (latency, throughput, error rate, and saturation or contention) through the entire stack from the inception of a unit of work (a transaction, a call, or whatever), through the entire set of services that comprise the application, and through the entire software and hardware infrastructure that support the application to the desired output or conclusion of that unit of work.
- Our data is deterministic. This means that we know for a fact that it is correct at the moment in time which the data represents, that it is not a rolled up average of other data points, and that it correctly represents the state of the unit of work to which it is associated. This also means that our data can be associated back to each individual unit of work (the high cardinality problem).
- Our data is comprehensive. This means that we have all of the necessary types of data across the entire stack and across all of the hardware and software components that comprise the application system. Comprehensive data includes having the metrics, traces, dependencies, and logs for every unit of work of interest. A unit of work could be a trace, a call between two methods on a server, a HTTP N-Tier transaction, or even a batch job.
- Our data is timely (as close to real-time as possible). This means that the lag in between when the unit of work occurs and the time the data is collected is as small as possible, as is the lag between the time that the data is collected and the time that it is available to be analyzed by the monitoring system. It is here where most monitoring vendors have a huge amount of work to do.
- Our data is not biased by the people that wrote the software that collects the data. It is here where I disagree that Observability is in some way tied to developers instrumenting their code. In my opinion having developers instrument their code (for metrics, traces, or anything else) is a terrible idea because it is not a good use of their time (they should be implementing functionality that drives the business, not writing monitoring code), because any developer who instruments their own code will be biased in doing it, and because in any large organization with multiple teams it will be impossible to get such code instrumentation to be done in any kind of a standard and consistent manner.
- As a corollary to the point directly above, our data is known to be objective. This leads us towards the monitoring industry as the source of this objective data, since the monitoring vendor is the only objective third party that can be counted on to collect this data without interjecting their own bias into the process.
- We understand that we cannot rely upon the vendors that produce the components (software or hardware) that comprise our stack to effectively instrument their components so that they produce the Four Golden Signals for any unit of work that flows through their component. This is again why we need to rely upon the monitoring vendors to give us an objective outside-in picture of what is going on.
- We understand the relationships between the components of the system that are producing the data for any one unit of work at any point in time. We understand what talks to what (flow) which is where the service tracing from Instana, Dynatrace, and OpenTracing come in, and the business transaction tracing by vendors like AppDynamics come in. We understand what runs on what (this Pod runs on this Node which runs on this Linux host). And we understand what is a member of what (this host is a member of this VPC, which is a member of this Availability Zone). This is where stupid log stores and stupid metric stores fall down. They rely upon statistics to infer correlation and therefore relationships which inevitably leads to false positives. Open source monitoring approaches also fall down here as they tend to produce silos of unrelated data (for example Prometheus and all of the OpenTracing derivatives) that are useless when it comes time to troubleshoot.
- We understand the configuration of the components of the system that are producing the data from any one unit of work at any point in time. This point and the one above are why CMDB’s and ADDM are both dead (data that is updated nightly is worse than useless).
- By virtue of being deterministic, comprehensive, timely, unbiased, and factually related across all of the components of the application system, our data can be trusted as the basis of automated actions (taking deterministic actions based upon statistically derived conclusions is a recipe for disaster).
Event Management – The Worst Approach to Observability
For all that has been written about Observability, no one has mentioned how inadequate the most widely prevailing method of managing IT systems and applications, event management is. Event Management means feeding the events from your N tools and platforms into an event management system that then deduplicates those events, prioritizes them and helps the team then resolve the issues.
There is no Observability in an event management system because waiting for a problem to occur is the anti-pattern to why we want Observability in the first place (to try to anticipate and prevent problems), and because events are completely lacking in the context required for them to be useful in the realm of Observability.
Automated Remediation is the Holy Grail
Our application systems are now being updated so frequently, are so complex and diverse and subject to so much dynamic behavior that we as humans are hard pressed to keep up with them. This is depicted in the image below.
Rapid Change, Diversity, Complexity, Continuous Innovation and
Dynamic Behavior Across the Stack
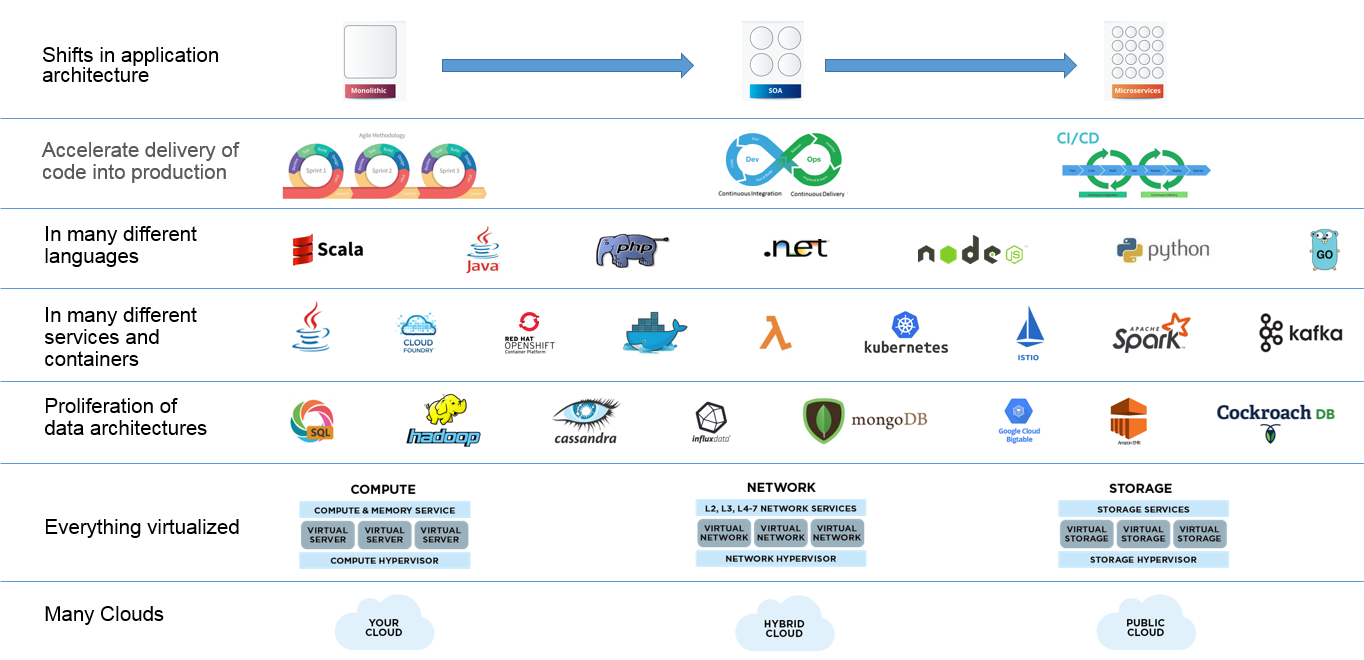
Automated remediation is the only viable approach to dealing with issues in systems like these. However in order for automated remediation to be possible it must be based upon data collected with the Observability principles in this post.
Summary
Observability is correctly placing the focus of monitoring upon the quality and the relevance of the data collected as a part of the monitoring, analysis and remediation process. The quality, comprehensiveness, accuracy and timeliness of our data must improve if we are going to be able to effectively manage our new highly complex and dynamic distributed systems effectively in production.

{kind=link}