New Relic has just announced New Relic One and a focus upon “entity-centric observability”. The announcement video featuring the CEO of New Relic, Lew Cirne is here. The idea is that the set of things that need to be monitored is exploding at an exponential rate, requiring not just metrics from all of these things, but an understanding of how they relate to each other. In other words the availability, performance, throughput, and error rate of each thing needs to be understood in the context of the things (and layers in the stack) it is dependent upon and that depends upon it. This is conceptually depicted in the image from the announcement below.
New Relic Entity Based Monitoring
A more realistic and complex image comes from Instana which features a Dynamic Graph that understands all of the relationships and dependencies for each monitored object or entity.
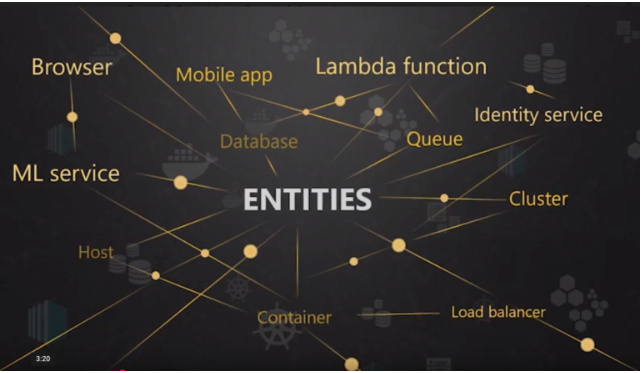
The Instana Dynamic Graph
The same idea exists in Dynatrace which calls the ability to understand relationships and dependencies Smartscape.
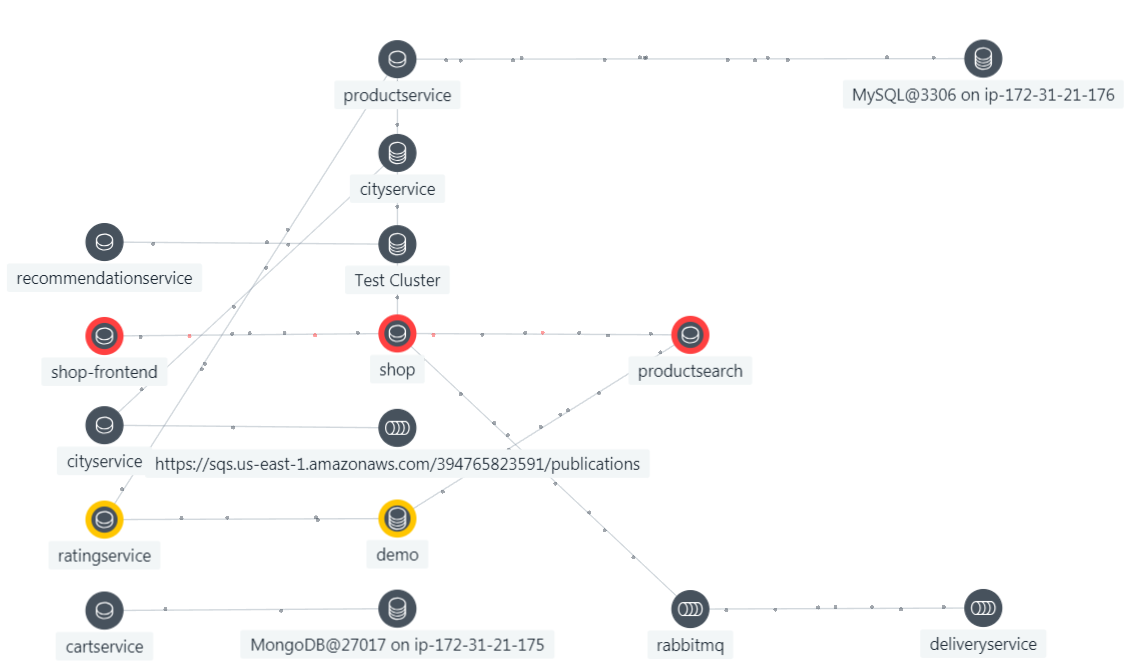
A Dynatrace Smartscape
The new Physics of Monitoring
Physics helps us understand how the physical objects in our universe are composed and how they relate to each other. Physics deals in a vast domain (consider all of the atoms and molecules in the universe and how they relate to each other).
The problem of understanding, managing and improving the behavior of all of the objects (entities) that will be connected to the Internet is similar to the problems of scale encountered in physics for the following reasons:
- Scale – We are not dealing with a couple of thousand servers or even a hundred thousand virtualized or cloud based images. We are dealing with millions and potentially billions of things that each have software in them that has to work. Decomposing monolithic applications into microservices is just a small example of this. We are not at the scale of physics yet, but it is starting to feel that way.
- Pace of Innovation – The pace of innovation in hardware and software technology continues to increase. This can only be true if what we have not invented yet exceeds what we have already invented so there is much more to come. Unlike the physical world where new elements are invented fairly rarely, this is commonplace in the world of devices and applications.
- Pace of Change – The pressure to deliver new functionality to market in a timely manner has fueled process and technology innovations that allow companies to release updates to software into production multiple times a day (somethings thousands of times a day). Imagine that if every time you looked into your back yard there were different trees with different shapes than before.
- Diversity – How many different pieces of hardware and software technology exist in your environment, and at what rate is this changing? Imagine if we were doubling the table of elements every year?
- Dynamic Behavior – Not only is the composition of the technology stack being changed constantly, but the operation of the environment is now highly dynamic as well. Transactions, applications, microservices, containers, orchestration systems like Kubernetes, cloud images, virtual servers, virtual networks and virtual storage are all highly dynamic layers of the stack which are changing constantly due to operator actions and automation. Managing a modern environment must feel like being in the vortex of a tornado – you are never sure what is going to happen next.
- Interconnectedness – The Internet was invented and designed to connect networks to each other. It has succeeded in a spectacular fashion resulting in things being dependent upon each other and affecting each other in ways that no one anticipated and which are most likely not predictable. This leads to a need to understand these relationships in real time and over time. Failure to understand the relationships will lead to the kind of chaotic situations that chaos theory was invented to understand.
The overarching new need here is to understand relationships (what each entity talks to and depends upon and what each entity depends upon). This is not new. The legacy CMDB was invented specifically to store configuration items and dependency relationships. Back in the day you could run discovery once a day (at night), and discover the environment and the relationships between all of the discovered items. Back in the day you could also count on that discovered set of relationships to remain accurate until the next time that you ran discovery.
So it is not that relationships and dependencies have suddenly become important, it is that real-time relationships and dependencies (stored over time) have become essential. So the state of every object or entity as described by its metrics needs to be understood in the context of the state of all of its related objects and metrics. This is, by the way, the only way that AI and ML stand a chance of doing deterministic root cause.
The New Economics of Monitoring
The history of the monitoring business at the application layer (called Application Performance Management or APM) is that there were relatively few things to be monitored that really mattered and that the APM vendors charged a lot of money for each thing that got monitored.
It was not that long ago that APM vendors charged between $10,000 and $15,000 per monitored server or Java Virtual Machine (JVM). This was justifiable because there were just not that many servers or JVM’s that needed an APM solution and those that did ran applications that were so important that the APM solution was easily cost justifiable.
Now the APM industry finds itself in an interesting situation. In its 2018 Magic Quadrant for Application Performance Monitoring, Gartner makes the following prediction, “By 2021, the need to manage increasingly digitalized business processes will drive enterprises to monitor 20% of all business applications with APM suites, up from 5% in 2017”.
What this means is that before the explosion in devices that need monitoring occurs, that the APM vendors only have succeeded in covering 5% of what existed in March of 2018. In order for the APM vendors to capture the forthcoming explosion in scope and scale the following issues will have to be addressed:
- The complexity of deploying an APM solution and the associated time to value will have to shrink dramatically. So much so that it should be completely automated with the APM agent discovering the monitored stack and automatically instantiating the required monitoring. Instana and Dynatrace have already done excellent work here.
- The breadth of coverage will have to dramatically expand. Not that long ago APM vendors supported two languages, Java and .Net. Now there are many languages and run time and there are going to be many cases of things that just do not look at all like a server with a JVM.
- The per device price to monitor with an APM solution is going to have to come down. That price is in the neighborhood of $2,500 per server or cloud image today. If the number of things to be monitored grows by a thousand times from where it is today, the physics of budgets is doing to dictate the required pricing adjustments by the APM vendors.
Summary
The APM business has been one of the most attractive and successful sectors in the software industry. It now faces an unprecedented opportunity for exponential growth, but only if it can adapt to the new physics and economics required to address this new opportunity.


{kind=link}