In the spirit of some year end housecleaning, maybe it is time to identify and get rid of some approaches to monitoring and management that do not work with the current realities of highly dynamic systems and applications running on distributed (and rented) infrastructure. Below we list four legacy technologies and approaches to monitoring and management, and explain what should replace them. In general these technologies and approaches are dead for the following reasons:
- Dynamic systems – starting with VMware (vMotion and Storage vMotion) in about the 2005 time-frame, the relationship between a virtual server and the host it ran on, and the relationship between a virtual datastore and its physical storage became dynamic. Dynamic means constantly changing, meaning that anything that would attempt to track these relationships would have to work continuously and in real time.
- Dynamic applications – scaling rules got their start up on the public clouds as dynamic scaling went hand in hand with consumption based pricing. Now with microservices orchestrated by Kubernetes, the sheer volume of things and their interactions defy legacy attempts to understand the composition of an application system at a point in time or over time.
- Rapid evolution of applications – microservices architectures combined with CI/CD now mean hundreds and sometime thousands of changes per day in production. Legacy approaches simply cannot keep up.
- Diverse application and data stacks – it used to be simple. An OS, a JVM and the code. Now the language world consists of Java, .NET, .NET Core, Python, PHP, Ruby, Node-JS, Scala, and Go (and some things that are not on this list). The diversity in languages is compounded by the diversity in runtimes for the languages ranging from things like Tomcat and SpringBoot, to Red Hat OpenShift. The database layer is now a very diverse set of technologies spanning multiple generations of SQL and NO-SQL databases.
Rest in Peace Legacy Monitoring

Application Discovery and Dependency Mapping (ADDM)
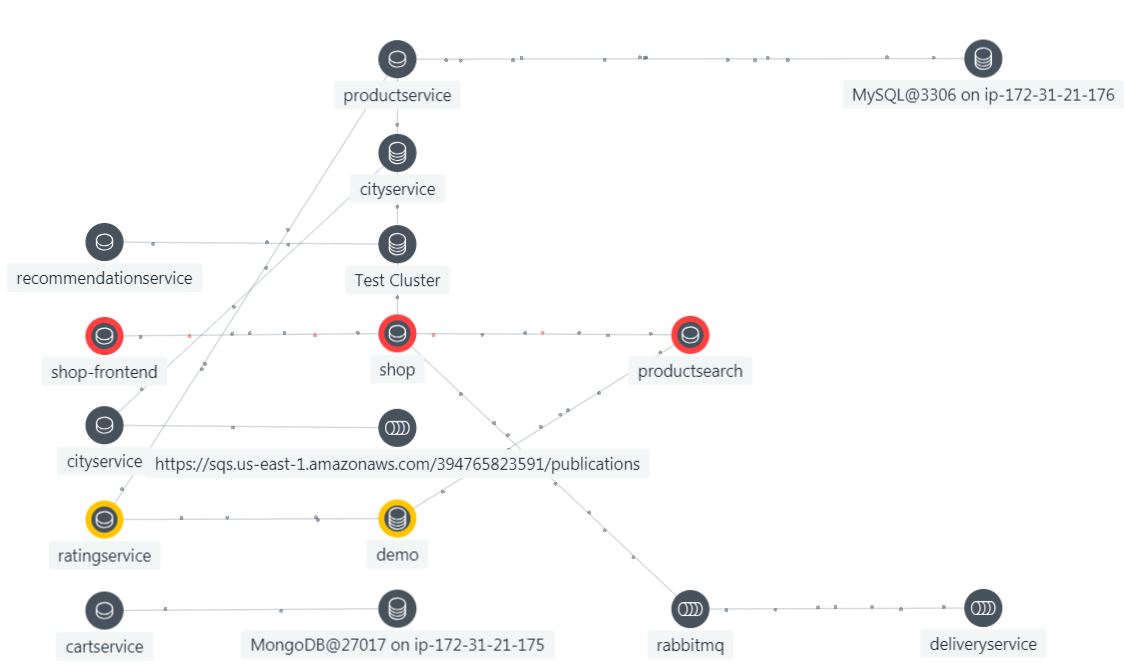
The idea behind ADDM was simple and powerful. Run a discovery process that found all of the applications in the environment, found what software and hardware infrastructure they ran on, captured the mappings, and then store the resulting configuration items and mapping in a CMDB (see below). Well it turned out that running this discovery process was resource intensive in and of itself, and that the discovery process placed a significant and noticeable load upon the production systems and applications that were being mapped.
The load and overhead created by the ADDM discovery process meant that this process had to be run only periodically, and then at night when production systems were not busy. Periodically in most shops meant once a week, or in the best of all worlds nightly. But even if the ADDM discovery process is run nightly, the results will be out of date as soon as a VM is vMotioned, and as soon as the CI/CD process pushes the first update of the new day. For this reason, ADDM is a legacy technology, that needs to go out with the end of year trash.
In fact it is not just ADDM that is a legacy technology. All after the fact discovery based approaches to understanding the state and relationships of applications and systems are now legacy and irrelvant. The only thing that now works is to capture state and relationships with the transactions, applications and traces at the moment they occur for each and every one of them.
The Configuration Management Database (CMDB)
If the process that feeds the CMDB is dead, then the CMDB is dead itself for a broader set of reasons. The broad reason is that the CMDB was simply not designed to be a real-time system with a massive and constant flow of incoming data, and a large number of concurrent queries. In fact this is part of an even broader problem, which is that the data back ends of most of the monitoring vendors cannot keep up in real time with the high cardinality data that comes from trying to understand state and relationship for every trace and every span in a highly dynamic system.
This need for a system that can keep up with a deluge of high cardinality data is what is leading the monitoring industry to transform into providers of Observability Platforms. See “Observability is About the Data” for a writeup about the implications of the kind of data and relationships that need to be captured.
IT Infrastructure Library (ITIL)
ITIL attempted to create standard processes for how IT should run. One of the important parts of ITIL was a change control committee whose job it was to slow down the rate of change enough to ensure that changes were less likely to create problems in production. Back when VMware vSphere was first going into production the standing joke was, “Don’t tell your Change Control Committee about vMotion”. Well now we cannot tell the Change Control Committee about Agile, DevOps and CI/CD either. Which means that the Change Control Committee and most of ITIL are now irrelevant legacy technologies and approaches.
Having declared the old process to be dead it is also fair to say that a new standard process has not emerged to take its place. DevOps and CI/CD are where the innovation is occurring, but the pace of innovation is so high that it is not possible yet to declare that a new process has been defined.
Event Management
Event Management is the process by which an IT organization reacts to the events and alarms that come into the support organization from a variety of sources (hardware and software infrastructure, applications, and a plethora of monitoring tools). The goal of the event management system is to identify the important problems, and then assist the support team in resolving them as fast as possible. Legacy event management systems used rules to prioritize events and to structure the workflows to resolve problems. Modern event management systems attempt to improve upon these rule based approaches with AI.
The problems with event management is that it is inherently reactive (wait for the problem to occur and then do something), and that the definition of the problems (the events and alarms) is spread out across a large number of items and systems with thresholds set by many different humans with many different priorities. So the incoming data is inherently flawed, and the process is flawed because it is inherently reactive with no ability to prevent problems.
Just like ITIL it is easy to declare event management to be problematic and dead, but it is a lot harder to identify what takes it place. The most likely solution will involve some combination of an AIOps platform (that understands objects, metrics, and relationships) and an Observability Platform (that understands the behavior of every single transaction, application, trace and span of interest).
Summary
The one thing that we do best in this industry is to deploy innovations into production that cannot be managed by whatever is in place to manage systems and applications. We did with with PC’s, LAN’s, Java, N-Tier Applications, virtualization, public clouds, and are doing it now with Agile, DevOps, CI/CD and Kubernetes. The only good thing to say about this is that it amounts to a full employment contract for those of us who are in the business of solving these problems.