AI is impacting every type of software, every vendor of software and every project that builds software for customers. Most of this software needs Observability (the ability to know if it is working correctly and take the proper actions to fix it if it is not working correctly). However Observability has some unique characteristics that impact how AI is going to affect it and maybe transform it.
The AI Landscape Pertaining to Observability
Looking at how AI has evolved suggests that there are currently five aspects of AI that have the potential to impact Observability:
- A New Technical Platform – AI runs on a new mix of GPU’s, high bandwidth memory, low latency networks and low latency storage that creates an entirely new set of problems in the realm of “did a problem in the infrastructure cause this”. This problem is exacerbated by the fact that in most cases this infrastructure lives in a cloud and is shared between customers. So it gives an entirely new life to the old “noisy neighbor” problem. This new platform includes an entirely new software stack beyond the LLM itself (see below), for example, Pinecone for a vector database, and LangChain for an AI application engineering framework.
- A New Definition of “Working Correctly” – The old definition of working correctly was whether the transaction completed (or failed), whether or not it completed quickly (latency and response time) and whether or not the required number of transactions completed in a unit of time (throughput). Now with LLM’s and Agents (see below) included in applications, and the entire AI stack being based upon statistics and probability, we now have to add the question, “did the AI do the right thing this time”. “This Time” is important because since the AI is probabilistic in nature (not deterministic), we cannot be sure it is doing the same thing every time even when it is given the same inputs.
- Large Language Models (LLM’s) – LLM’s understand what they have been trained on which includes the languages that humans use to converse with each other, and programming languages that are used to tell computers what to do. LLM’s can therefore be used to help understand Observability data and alerts, and most importantly can be used to at least partially automate the process of writing code. The use of LLM’s to write code will make it easier to build new code, which will in turn hasten the process of getting new code into production, which will in turn dramatically expand the market (the TAM) for Observability as all of this new code will need to be monitored. What LLM’s cannot do currently is continuously learn the behavior and patterns of an application in production, which means that LLM’s cannot be used to automate problem detection and resolution. A different flavor AI (Dynatrace Davis calls this “Causal AI”) is needed for this purpose.
- Agents – Agents are software programs that can be built on top of LLM’s and using the Model Context Protocol (see below) also access any source of data (for example Observability data, if the vendor who is the source of that data has built an MCP Server). Coralogix has surfaced their data via an MCP Server. Amazon Web Services has surfaced both its CloudWatch and Applications Signals data with MCP servers. Dynatrace has open sourced its MCP server on GitHub. By accessing an LLM and its intelligence, AND Observability data from an MCP Server it is now possible to build a problem detection and resolution process that leverages both. Note that it is up to the builder of the Agent that uses all of this data to include the intelligence needed to interpret this data as neither the LLM or the Observability data itself contain this intelligence.
- MCP, MCP Servers, and MCP Agents – The Model Context Protocol (MCP) was introduced by Anthropic in 2024. MCP defines the structure of the data accessed to be accessed by an agent so that the agent understands the meaning of this data. The most common way to describe a set of data via MCP is to build an MCP Server which is what Coralogix (see above) has done. A note of caution is warranted here. Just because an Agent can access Observability data from an MCP server does not mean that that Agent can solve a problem identification and resolution problem. What is needed is a layer of AI that understands these problems and how to solve them (see Dynatrace Davis above).
Unique Problems Using AI in Observability
As explained above, LLM’s are not natively trained on Observability data, and adding that data to Agents via the MCP does not solve the problem detection and resolution process either. This is because of the following somewhat unique aspects of the Observability problem:
- Observability data is not easy to get, nor is it “free”. While data about the infrastructure (the cloud or the on-premise environment) is readily accessible via various API’s, data about the behavior of applications is not readily accessible. You either need to buy, deploy and test an Observability agent from an Observability vendor, or build Open Telemetry into your application (which you do not need to buy, but you do need to burn precious developer time to build the integration, test it and maintain it).
- Getting application level Observability data is a constantly changing problem. The manner in which applications are built and the manner in which they are supported in production are constantly evolving and changing. AI is one example. Many of the applications that have been built as a part of the Digital Transformation projects over the years face important constituents (prospects, customers, vendors, partners). Building an AI based support mechanism into these applications is a natural extension of them. This requires building access to an LLM into the application which in turn need to be monitored with Observability. This is why every leading Observability vendor has added LLM Monitoring to their products.
- LLM’s cannot handle Observability data (at least not yet). LLM’s are based upon being trained which happens at best a couple of times a year. Observability data is constantly changing in real time. Problems need to be detected in real time and resolved as quickly as possible once detected. LLM’s are also based upon the concept of languages. So in order for an LLM to understand something, a language for that thing must exist and that thing must be described in that language. There is at this point no commonly agreed upon language and language conventions for Observability. If all of the Observability vendors would get together and tag their data in a common manner that would be a good first step. But to really solve this problem every developer of every application would need to follow a common set of conventions and terms when their application is monitored.
The Future of AI in Observability
Since LLM’s can be used to automate the writing of code, the short term impact of AI upon Observability is simply to dramatically expand the number of applications that need monitoring and therefore the market (the TAM) for Observability. The long term impact of AI upon Observability to for AI to enable the automation of the Observability process:
- Automatic Problem Detection – this means knowing that a problem is occurring and notifying the Observability system and the humans that manage it that this problem exists. And it means doing this without missing problems (false negatives) and without generating false alarms (false positives) which in turn means No Hallucinations. Current Observability platforms are unable to do this first step for a broad set of applications and problems so there is much work to be done just on this first step.
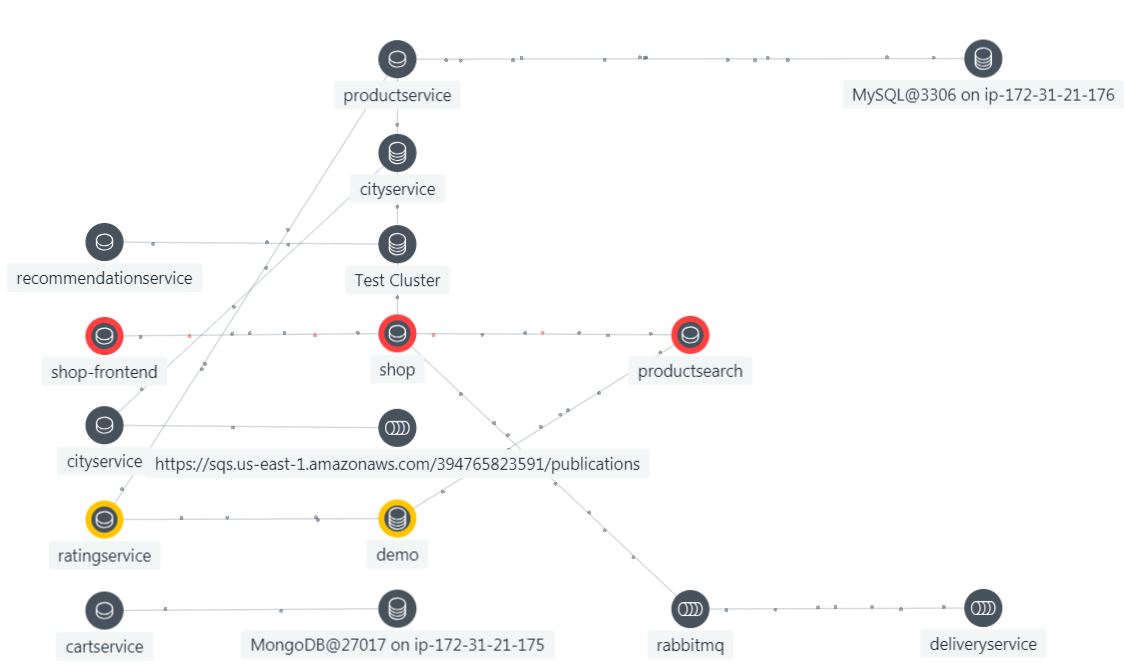
- Automatic Root Cause – once a problem has been detected and determined to be a real problem then comes the task if figuring out what caused it. The first step in this process is figuring out what is related to the part of the application that is having the problem. This requires a real-time topology and dependency map for the application software, system software and infrastructure software that support the application instance that is having the problem. Dynatrace SmartScape and IBM Instana implement such maps. Leveraging such a map with a casual reasoning engine appears to be a productive approach as explained by this article by Causely.
- Automatic Problem Resolution – so exactly what change needs to occur to actually fix the problem? Much progress needs to be made here.
- Automatic Fix Verification – so did the change actually solve the problem and did it not create any new problems in the process? Much progress is also needed here.
In summary, while LLM’s have advanced AI in a very impressive manner, there is a long way to go before AI can fully automate the resolution of Observability problems. The great news is that the number of such problems is going to increase dramatically due to ability of LLM’s to write code. So the incentives certainly exist for the investments in the required Observability improvements to occur.